Stanford University: Edge ML Accelerator SoC Design Using Catapult HLS
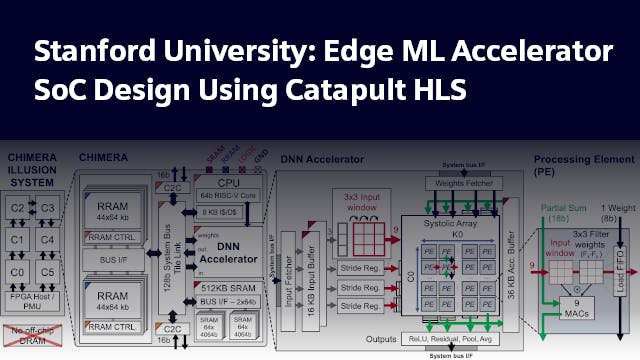
High-Level Synthesis (HLS) offers a fast path from specification to physical design ready RTL by enabling a very high design and verification productivity. HLS handles several lower-level implementation details, including scheduling and pipelining, which allows designers to work at a higher level of abstraction on the more important architectural details. Designing at the C++ level allows for rapid iterations, thanks to faster simulations and easier debugging, and the ability to quickly explore different architectures. HLS is a perfect match for designing DNN accelerators, given its ability to automatically generate the complex control logic that is often needed. This webinar will describe the design and verification of the systolic array-based DNN accelerator taped out by our group, the performance optimizations of the accelerator, and the integration of the accelerator into an SoC. Our accelerator achieves 2.2 TOPS/W and performs ResNet-18 inference in 60 ms and 8.1 mJ.
What you will Learn
- Effective use of HLS for ML accelerator design
- Analyzing performance and optimizations
- Integrating an HLS design into an SoC
Who Should Attend
- System architects and RTL/HW designers interested in using HLS for ML accelerators
Meet the speaker

Kartik Prabhu
PhD student in Electrical Engineering
Kartik is a PhD student in Electrical Engineering at Stanford University advised by Professor Priyanka Raina. He received his M.S. degree in Electrical Engineering from Stanford University in 2021 and B.S. degree in Computer Engineering from Georgia Tech in 2018. His research focuses on designing energy efficient hardware accelerators for machine learning.
Related resources

DDRx Memory Interface: The most complicated modern bus
This paper dives into what makes DDRx challenges so complicated, their cost, and what you can do to resolve

Using job distribution to optimize signal integrity analysis through parallel simulation
Computational job distribution is an important component to scaling and optimizing any signal integrity analysis.

Join us at electronica 2024 and see simplified electronic systems design
The world of electronics design is constantly evolving, pushing the boundaries of complexity. At Siemens, we understand the challenges that…